Explanations of the DeepSeek R1 Technical Paper
January 2025
The new model R1 has raised a lot of interest… and a lot of BS 🙃. Here is the explanation given by the DeepSeek chatbot as it read directly the original technical paper ( https://arxiv.org/html/2501.12948v1). The text below is from the chatbot, not me. 🤝💪
What to remember from the Introduction
Below is a rephrased version of Section 1 of the arXiv technical paper from the provided URL, with technical jargon explained briefly for clarity. I’ve focused on presenting the facts while simplifying the language where possible.
Rephrased Section 1: Introduction
Background and Motivation
Reinforcement learning (RL) is a type of machine learning where an agent (an AI system) learns to make decisions by interacting with an environment (a simulated or real-world setting). The agent receives rewards (feedback signals) based on its actions and aims to maximize the total reward over time. RL has shown great success in areas like game playing, robotics, and autonomous systems.
However, traditional RL methods often require massive computational resources and large amounts of data to achieve good performance. This makes them impractical for many real-world applications, especially those with limited resources or where data collection is expensive. To address these challenges, this paper introduces DeepSeek, a new RL framework designed to improve efficiency, scalability, and adaptability.
Key challenges in RL
Sample Efficiency : Traditional RL methods often need millions or billions of interactions with the environment to learn effectively. This is called sample inefficiency, and it makes RL expensive and time-consuming.
Scalability: As tasks become more complex, the computational resources required to train RL models grow exponentially. This limits the applicability of RL in resource-constrained settings.
Adaptability: Many RL systems are designed for specific tasks and struggle to generalize to new or slightly different environments. This lack of adaptability reduces their usefulness in real-world scenarios.
DeepSeek’s Contributions
The DeepSeek framework addresses these challenges through several key innovations:
Model-Based RL : Instead of relying solely on trial-and-error interactions, DeepSeek uses a learned model of the environment to simulate and plan actions. This reduces the need for extensive real-world data collection.
- Explanation: A model-based RL system builds a representation of how the environment works, allowing the agent to “imagine” outcomes without always interacting with the real world.
Meta-Learning: DeepSeek incorporates meta-learning techniques, enabling the agent to adapt quickly to new tasks with minimal additional data.
- Explanation: Meta-learning (or “learning to learn”) allows the agent to use knowledge from previous tasks to learn new tasks faster.
Distributed Training: DeepSeek employs a distributed training framework that optimizes computational resources, making it scalable and efficient.
- Explanation: Distributed training splits the workload across multiple machines or processors, speeding up the learning process.
Human-in-the-Loop : DeepSeek integrates human expertise into the training process, using demonstrations and feedback to guide the agent’s learning.
- Explanation: Human-in-the-loop systems involve humans providing input (e.g., demonstrations or corrections) to improve the agent’s performance.
Safety and Robustness : DeepSeek prioritizes safety and robustness by designing reward functions and constraints that ensure the agent behaves reliably in real-world applications.
- Explanation: Robustness refers to the system’s ability to perform well even in uncertain or changing environments, while safety ensures the agent avoids harmful or unintended behaviors.
Applications
DeepSeek’s framework is designed for a wide range of applications, including:
- Robotics : Training robots to perform complex tasks with limited data.
- Autonomous Systems : Developing self-driving cars or drones that can adapt to new environments.
- Healthcare : Creating AI systems that assist in medical diagnosis or treatment planning.
Summary
DeepSeek represents a significant step forward in making RL more practical and accessible for real-world applications. By improving efficiency, scalability, and adaptability, DeepSeek enables the development of AI systems that can learn effectively with fewer resources and in diverse environments.
Explanations of Technical Jargon
- Reinforcement Learning (RL): A type of machine learning where an agent learns by interacting with an environment and receiving rewards for its actions.
- Agent : The AI system that learns and makes decisions in an RL framework.
- Environment : The setting in which the agent operates, which could be a simulation or the real world.
- Rewards : Feedback signals that guide the agent’s learning by indicating how well it is performing.
- Sample Efficiency : The ability of an RL system to learn effectively with fewer interactions with the environment.
- Model-Based RL : An approach where the agent learns a model of the environment to simulate and plan actions.
- Meta-Learning : A technique where the agent learns to adapt quickly to new tasks by leveraging prior experience.
- Distributed Training : A method of training AI models by splitting the workload across multiple machines or processors.
- Human-in-the-Loop : A system where humans provide input (e.g., demonstrations or feedback) to improve the agent’s learning.
- Robustness : The ability of a system to perform well in uncertain or changing environments.
- Safety : Ensuring that the agent avoids harmful or unintended behaviors.
Let me know if you’d like further clarification or additional sections rephrased!
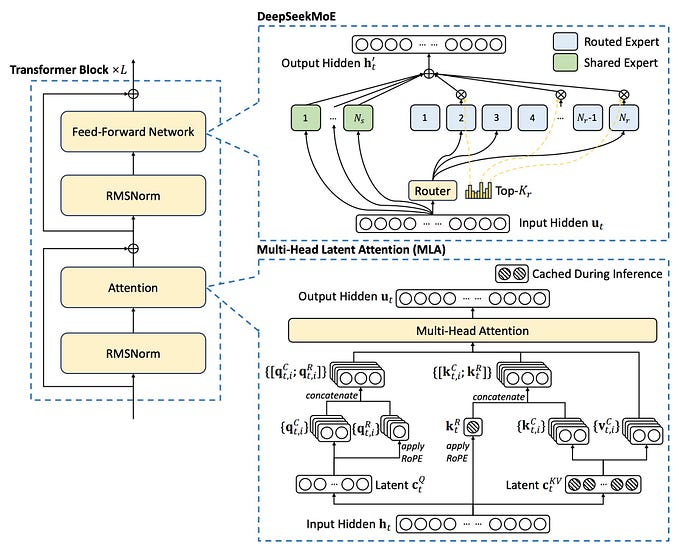
The Distillation Process
The distillation process in machine learning, particularly for Large Language Models (LLMs), involves transferring knowledge from a larger, more complex model (often called the teacher model) to a smaller, more efficient model (called the student model). Here’s a breakdown of the process:
- Teacher Model : A large, high-performing model (e.g., DeepSeek-R1) that has already been trained and fine-tuned to excel at specific tasks, such as reasoning or coding.
- Student Model : A smaller, less complex model (e.g., Qwen2.5–32B or Llama3) that is intended to replicate the teacher model’s performance but with fewer parameters and computational requirements.
- Training Data : This can include:
- Reasoning Data : Examples of problems and solutions generated by the teacher model (e.g., Chain-of-Thought reasoning steps).
- Task-Specific Data : Datasets related to the tasks the student model is being trained for (e.g., mathematics, coding, or general question-answering).
- Human Preferences : Data that aligns the student model with human values or preferences, ensuring it generates useful and ethical outputs.
Processes Carried Out
Knowledge Transfer:
- The teacher model generates outputs (e.g., reasoning steps, answers to questions) for a set of inputs. These outputs serve as “soft labels” or guidance for the student model.
- The student model is trained to mimic the teacher model’s behavior by minimizing the difference between its outputs and the teacher’s outputs.
Fine Tuning
- The student model is fine-tuned on the teacher model’s outputs, often using supervised learning. This helps the student model learn the reasoning patterns and problem-solving strategies of the teacher model.
- In some cases, reinforcement learning (RL) is also used to further refine the student model’s performance, especially if the teacher model was trained using RL.
Alignment with Human Preferences:
- The student model may undergo additional training to align its outputs with human preferences, ensuring it generates responses that are not only accurate but also ethical and user-friendly.
Evaluation and Iteration:
- The distilled student model is evaluated on benchmarks (e.g., AIME 2024, MATH-500) to measure its performance.
- If necessary, the distillation process is repeated or adjusted to improve the student model’s performance.
Outputs:
Distilled Student Model: A smaller, more efficient model that replicates the reasoning capabilities and performance of the teacher model. For example:
- DeepSeek-R1-Distill-Qwen-7B : A 7-billion-parameter model distilled from DeepSeek-R1.
- DeepSeek-R1-Distill-Llama-14B : A 14-billion-parameter model distilled from DeepSeek-R1.
Improved Performance on Benchmarks:
- The distilled model achieves competitive results on reasoning, coding, and knowledge-based tasks. For example:
- A 55.5% pass@1 score on AIME 2024 for the 7B model.
- A 72.6% pass@1 score on AIME 2024 for the 32B model.
Open-Source Models:
- The distilled models are often released to the research community, enabling others to build on the work. For instance, the distilled Qwen and Llama series models are open-sourced.
Why Distillation is Useful
Efficiency: Smaller models require less computational power and memory, making them more practical for real-world applications.
Accessibility: Distilled models can be deployed on devices with limited resources, such as smartphones or edge devices.
Performance: Despite being smaller, distilled models can achieve performance close to that of the teacher model, especially in specific tasks like reasoning or coding.
Example in Context
In the paper, DeepSeek-R1 (the teacher model) was distilled into smaller models like Qwen2.5–32B and Llama3. The distilled models outperformed models trained directly with RL, demonstrating that the reasoning patterns discovered by the larger teacher model are crucial for improving smaller models’ capabilities.
Let me know if you’d like further clarification!
Bonus: My 2 cents
As you can see the resulting text is very easy to understand. No need for any influencer to tell you what to think. 🤝💪. Now if you read directly the technical Paper, we see that:
1️⃣ instead of training their model with huge amounts of expensive curated data, they made a simulation of the real world and let the model learn by comparing its reasoning with the actual simulation.
2️⃣ when the learning started from scratch (pure Reinforcement Learning), they noticed that the model gave correct results but sometimes reasoned in a very convoluted way, mixing English and Chinese explanations: R1-Zero.
3️⃣ when they started the learning with examples of human expert reasoning (cold-start Supervised Fine-Tuning), and rewarded sound reasoning, the results were better than the best Open-AI models: R1.
4️⃣ when they (distilled) transferred the learned reasoning to smaller existing models, these models perform better than models much much bigger.
👉 Distinguished CEOs (Perplexity AI and Scale AI) say that the Chinese didn’t copy the Americans, they invented something much better.
- CEO of Perplexity AI: https://youtu.be/WEBiebbeNCA
- CEO of Scale AI: https://youtu.be/x9Ekl9Izd38
Originally published at https://www.linkedin.com.
![Reading Notes of ElizaOS [2]](https://miro.medium.com/v2/resize:fit:679/1*CYrfZEC_xKbpReHqYQF0MQ.png)